I’ve been exploring functional programming, and spent some time implementing HAMT- and CHAMP-backed hashmaps in Koka last semester. I think Koka has some valuable ideas, and HAMT and CHAMP maps are simple and useful data structures, so I decided to write about my experience here.
What are HAMTs and CHAMPs?
The Hash-Array Mapped Trie (HAMT) is a simple but powerful variant of the trie data structure. Instead of using the characters of a string to navigate the search tree, HAMT uses slices of a computed hash, where each slice of the hash is the index for a node in the tree. Here’s an example where we index into a HAMT with four children per node, 6-bit hashes, and 2-bit indices:
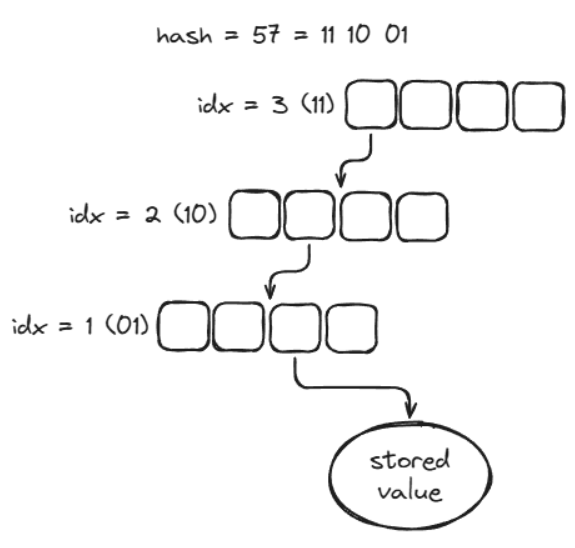
Optimized HAMT implementations often use 16 or 32 children per node. They have great performance characteristics, with O(log_32 n) scaling (some people jokingly refer to this as “effectively constant”). And because of their tree structure, they can be used persistently (i.e. old versions of the tree are kept available) without copying the entire map every time it’s modified. This makes HAMTs ideal in functional languages where data is immutable by default, like Clojure and Scala.
The Compressed Hash-array Mapped Prefix-tree (CHAMP) is an evolution of the HAMT introduced by Steindorfer and Vinju in 2015. CHAMP has several improvements that make HAMT more performant. One of the most important improvements (and the one I implemented) is that CHAMPs split their children into two arrays instead of one. One array contains values, and the other contains references to subtrees. This split increases cache locality during iteration in two ways: values are allocated together, and traversal avoids alternating between descending subtrees (i.e. chasing pointers) and returning values.
What is Koka?
Koka is a research-oriented functional programming language with a focus on safety and performance. It supports algebraic effects, uses reference counting instead of garbage collection, and has some novel syntax, including context constructors and a “functional but in place” (FBIP) keyword, that allow for efficiently building and modifying data structures while maintaining an idiomatic functional code style. Koka’s documentation does a great job of explaining those features, but they’re interesting to me because they approach performance with the explicit goal of matching (or at least getting close to) the runtime performance and memory footprint of lower level languages like C. This paper shows that focus, with the authors using Koka’s features to get within 2X the speed of C. I wanted to use those features in my map implementations, but I ran into a couple of issues, which I’ll get into below.
Implementation
Here’s a link to the code: https://github.com/Caid11/koka-hamt-champ-maps
The implementation is fairly straightforward. lib/map/map.kk contains functions to instantiate array-, HAMT-, and
CHAMP-backed maps, with lib/map/arrayBacked.kk, lib/map/hamtBacked.kk, and lib/map/champBacked.kk containing each
respective implementation. As far as I could tell, Koka doesn’t have a way to specify that types implement a common
interface, so I had to make a parent type to dispatch function calls for each implementation.
The array-backed implementation is what one would expect. The HAMT and CHAMP implementations are also fairly straightforward. However, I struggled to implement indexing correctly. Most HAMT and CHAMP maps use a dense array for their children, where there are no empty array slots between array elements, and the elements are shifted if necessary during insertion. For example, if elements are inserted for indices 0, 2, and 3, they are initially at slots 0, 1, and 2 of the array. Later, if an element is inserted for index 1, the elements in slots 1 and 2 are shifted to make space for the new element. This provides better cache locality and gives us the option to lazily grow the array to reduce our memory footprint.
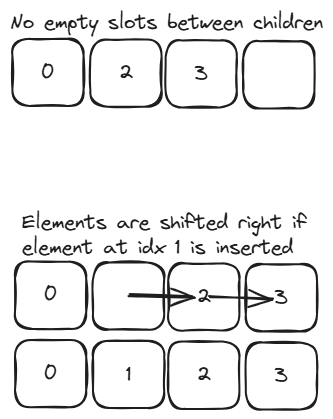
Because elements aren’t stored at their “true” indices, we need some piece of data to track where they’re actually stored. HAMTs use a bitmap where each bit tracks if a given index has been inserted into the array. We can use that bitmap and some clever bitwise arithmetic to efficiently calculate the current slot for a given index. Steindorfer and Vinju’s paper has a code snippet showing the calculation in Java:
static final int mask(int hash, int shift) {
return (hash >>> shift) & 0b11111;
}
static final int index(int bitmap, int bitpos) {
return Integer.bitCount(bitmap & (bitpos - 1));
}
// HAMT indexing with 1-bit state
Object getKeyOrNode(K key, int hash, int shift) {
int bitpos = 1 << mask(hash, shift);
int index = WIDTH * index(this.bitmap, bitpos);
if (contentArray[index] != null) {
return contentArray[index];
} else {
contentArray[index + 1];
}
}
It looks a little complicated, but the basic idea is straightforward. To calculate the array slot for an index, the code above extracts the part of the hash containing the index, then counts all of the elements present in the array before the one we’re interested in, which gives us the slot containing our index. Here’s a simple example I worked through to understand it, which uses 4 children per node, 4-bit hashes, and 2-bit indices:
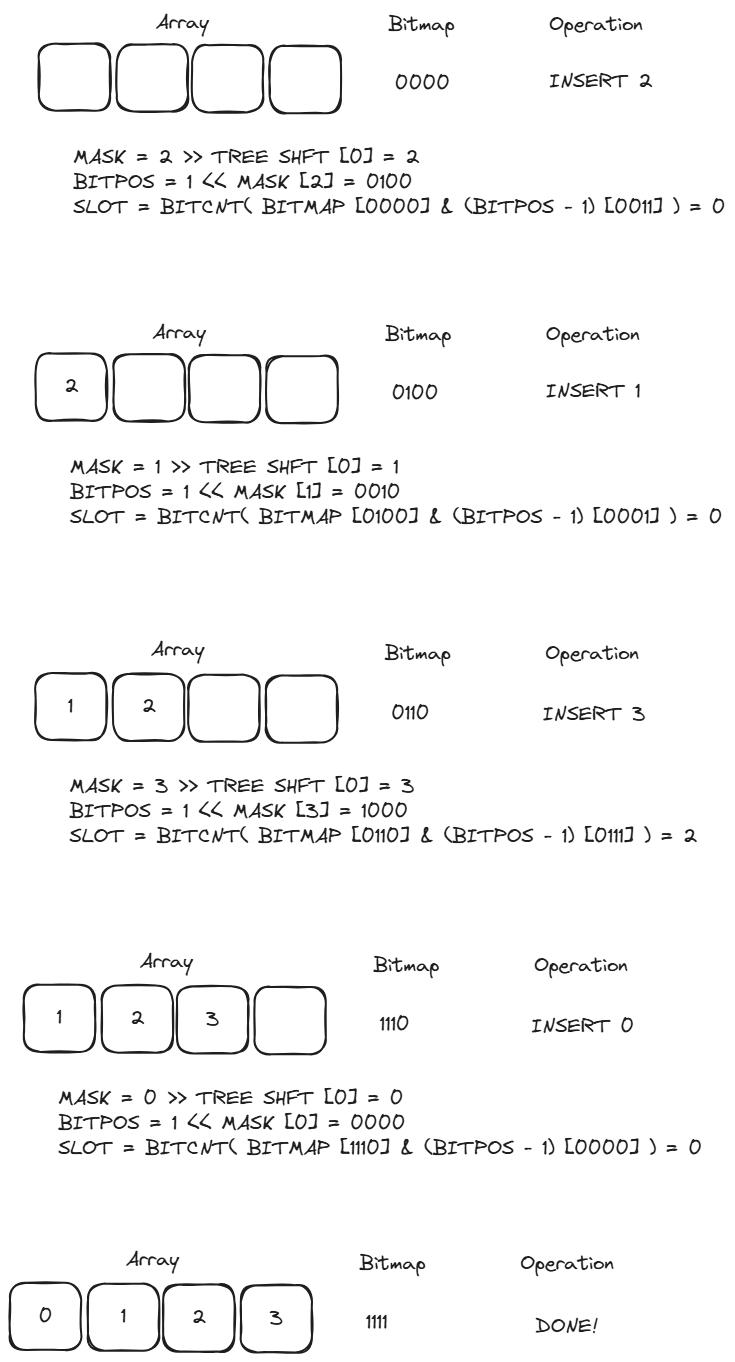
In the code listing and example, there are references to a parameter called “shift” or “tree shift”. That’s the number of bits we need to shift right to get our index. Because the example never descends past the first node, that value is always 0. If we descended into the tree, we’d add 2 to our shift value for every node we descended, which would allow us to extract the next index from the hash.
CHAMP maps either require two bitmaps (one for the array of values, and one for the children), or one bitmap with the optimized indexing scheme described by Steindorfer and Vinju. In my case, I stuck with two bitmaps, because I hadn’t profiled my CHAMP implementation enough to see if the optimized scheme would be worthwhile for me.
Koka Challenges
I think it’s worth discussing my experience writing Koka. It’s relatively new, so there are still a few rough edges. The main one for me was Koka’s optimizer, which hung on my code fairly often. The issue was simultaneously difficult to work around (I found that refactoring my code didn’t seem to avoid the hangs), but difficult to construct reproducers for (the optimizer seemed to do fine when I tried to reduce the code involved). One of the hangs forced me to use linked lists instead of arrays to store each node’s children, which likely degrades performance and is a bit disappointing.
Another challenge was Koka’s type system. It can express more than any other language I’ve worked with (it can even model local and global heap access as effects!), but that power comes with a learning curve. As a novice functional programmer, I found it difficult to understand many of the error messages, especially when I was trying to compose effect types. I also accidentally constructed infinite types several times. Luckily, Koka’s type inference is quite robust, so I was able to remove my type specifiers and carry on.
The last challenge was a limitation with context constructors. Context constructors essentially let you create a chain of constructors as you recursively call functions, then “apply” them to quickly and efficiently construct the data structure you want to return. Koka’s authors used context constructors in their “Functional Essence…” paper to get almost C-like performance with tree data structures, and I was hoping to use them for this project. Unfortunately, it looks like you can only chain constructors of a single type. For example, you could have a chain of Cons( x, Cons(y, …) calls. But in my case each node contained an array of its children, so I needed to express a chain of alternating Node/Array/Node constructors, but I couldn’t see a way to do that. The syntax may allow that, but it isn’t yet well documented and I couldn’t see any examples doing so. Hopefully it either is possible or will be possible in the future, as being able to use constructor contexts with multiple types would make them useful for many more data structures.
Performance Results
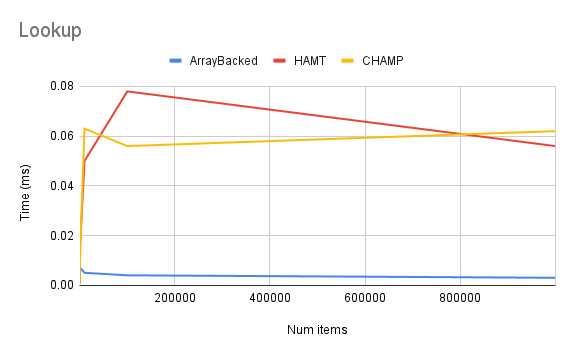
My results were in line with what I expected: lookup and iteration was slightly slower for HAMTs and CHAMPs than the array-backed implementation, while insertion and deletion were much faster. The CHAMP implementation was generally a little faster than HAMTs. Here are a few charts showing my results:
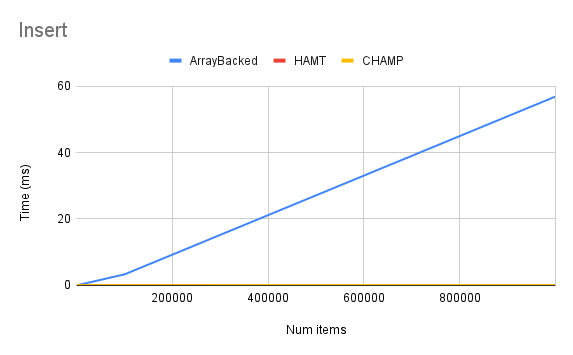
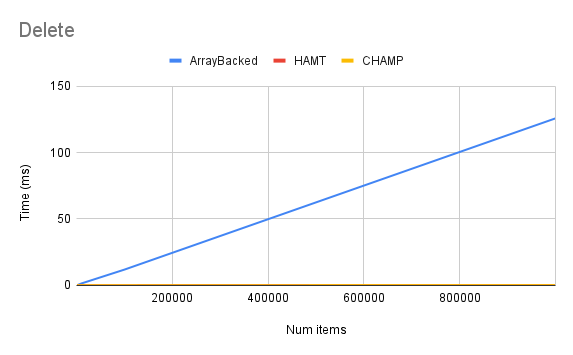
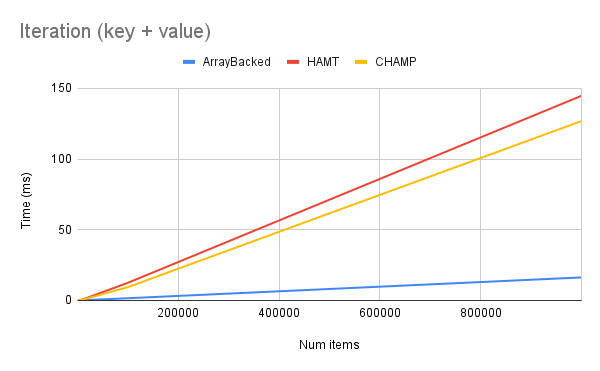
Closing Thoughts
Overall, I really enjoyed working with Koka, and I’m surprised at how powerful and simple HAMTs and CHAMPs are. I’m a little surprised more hasn’t been written about them, but they’re available in many functional languages’ standard libraries. Perhaps language implementers are familiar with the existing literature, and most programmers can simply use the standard library.